Google Summer of Coding Week 10&11
So, this is my 8th blog about two weeks(10th and 11th). Previously, I talked about establish an ASR system based on PaddlePaddle and Kaldi. These two weeks, I finished a complete example using Aishell dataset on my local PC. The details will be shown in this blog.
Establish an ASR system based on PaddlePaddle and Kaldi
1. Model Overview
The acoustic model in this example is a multi-layer stacked LSTMP structure. The structure uses convolution to extract the initial features, uses multi-layer LSTMP to model the temperal relation. The loss function is the cross entropy. LSTMP(LSTM with recurrent projection layer) is the extension of the traditional LSTM, adding a mapping layer on the basis of LSTM. The layer maps the hidden layer to a lower dimension and goes into the next time step. The structure also reduces the size and computation complexity of LSTM, at the same time improves the performance of LSTM.
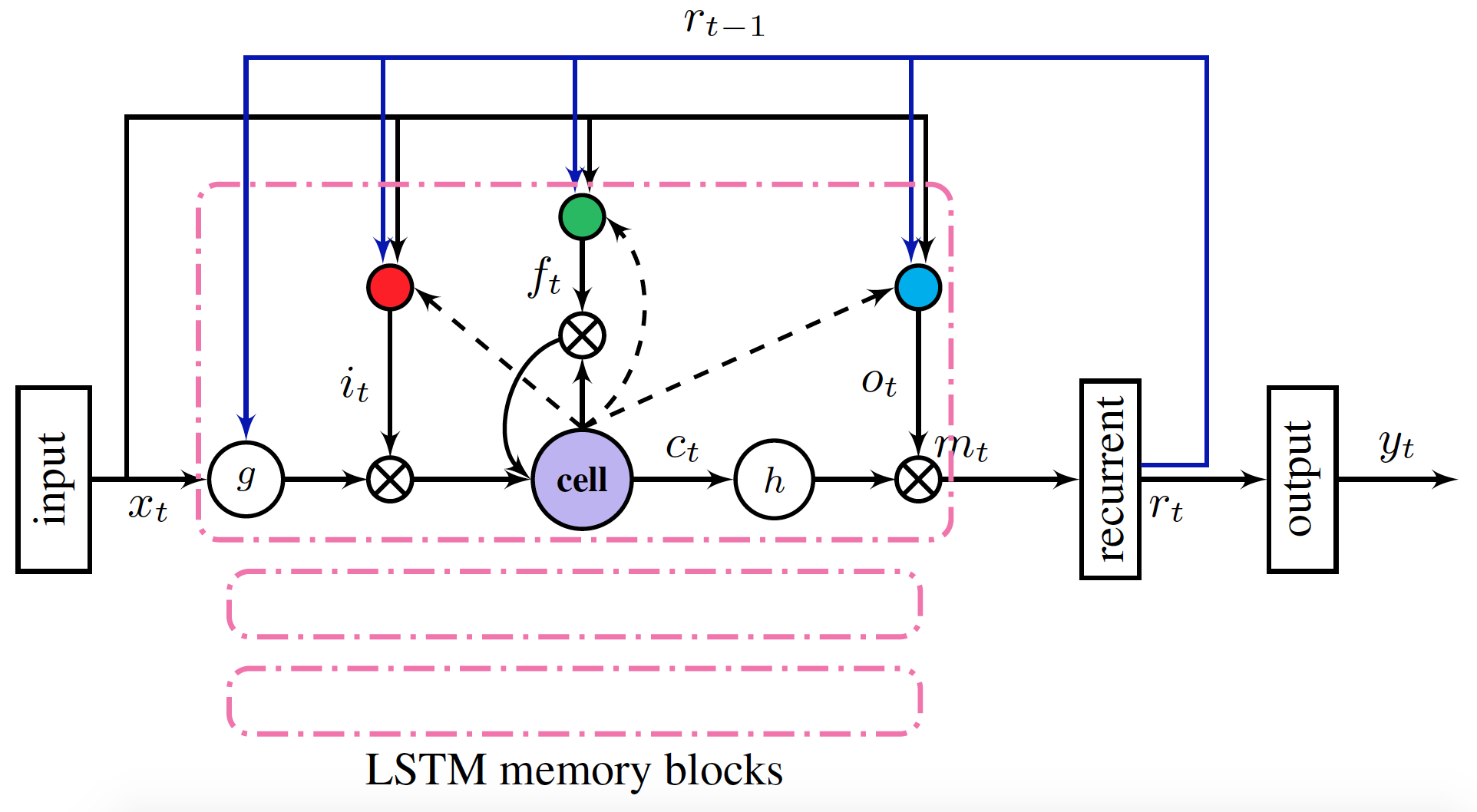
2 Installation
Kaldi
The decoder of the example depends on Kaldi, install it by flowing its intructions.Then set the environment variable KALDI_ROOT:
$ export KALDI_ROOT=<Installation path of kaldi>Decoder
$ git clone https://github.com/CynthiaSuwi/ASR-for-Chinese-Pipeline.git
$ cd kaldi/decoder
$ sh setup.sh3 Data Preprocessing
Refer to the data preparation process of Kaldi to complete the feature extraction and label alignment of audio data.
4 Demo
This section takes the Aishell dataset as an example to show how to complete data preprocessing and decoding output. Aishell is a Mandarin Chinese speech dataset opened by the Hill Beeker Co in Beijing. It is 178 hours long and contains 400 voice from different accents. The original data can be obtained by openslr. To simplify the process, the preprocessed dataset has been provided for download:
$ cd kaldi/examples/aishell
$ sh prepare_data.shAfter the download is completed, the training process can be analyzed before starting training:
$ sh profile.shExecute the training:
$ sh train.shThe cost function and the trend of accuracy in the training process are shown below:
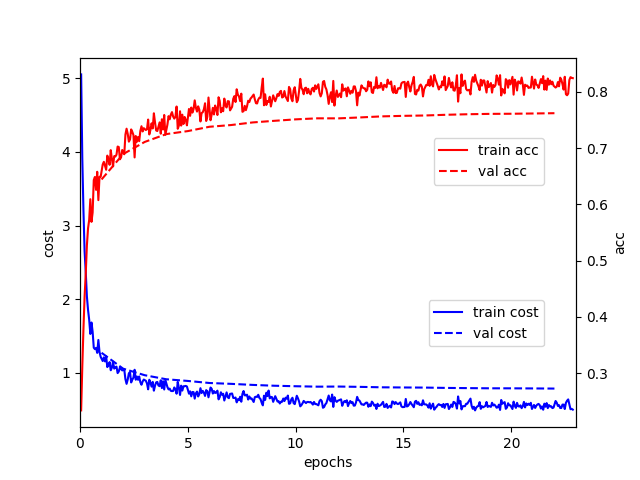
After completing the model training, the text in the prediction test set can be executed:
$ sh infer_by_ckpt.shIt includes two important processes: the prediction of acoustic model and the decoding output of the decoder. The following is a sample of the decoded output:
BAC009S0764W0239 十一 五 期间 我 国 累计 境外 投资 七千亿 美元
BAC009S0765W0140 在 了解 送 方 的 资产 情况 与 需求 之后
BAC009S0915W0291 这 对 苹果 来说 不 是 件 容易 的 事 儿
BAC009S0769W0159 今年 土地 收入 预计 近 四万亿 元
BAC009S0907W0451 由 浦东 商店 作为 掩护
BAC009S0768W0128 土地 交易 可能 随着 供应 淡季 的 到来 而 降温Each row corresponds to one output, beginning with the key word of the audio sample, followed by the decoding of the Chinese text separated by the word. Run script evaluation word error rate (CER) after decoding completion:
$ sh score_cer.shIts output is similar as below:
Error rate[cer] = 0.101971 (10683/104765),
total 7176 sentences in hyp, 0 not presented in ref.Using the acoustic model of 20 rounds of training, we can get about 10% CER for recognition results on the Aishell test set.
5 Conclusion
This wraps up my report on weeks 10 and 11. Next post will be my final evaluation. Thank you for reading :-)