Wavenet-demo
Speech-to-Text-WaveNet : End-to-end sentence level Chinese speech recognition using DeepMind’s WaveNet
A tensorflow implementation for Chinese speech recognition based on DeepMind’s WaveNet: A Generative Model for Raw Audio.(Related Paper)
The architecture of Wavenet is very interesting, integrating dilated CNN, residual network, CTC, the gate in LSTM, the 1*1 convolution kernel and other classic structures. The architecture is shown in the following figure: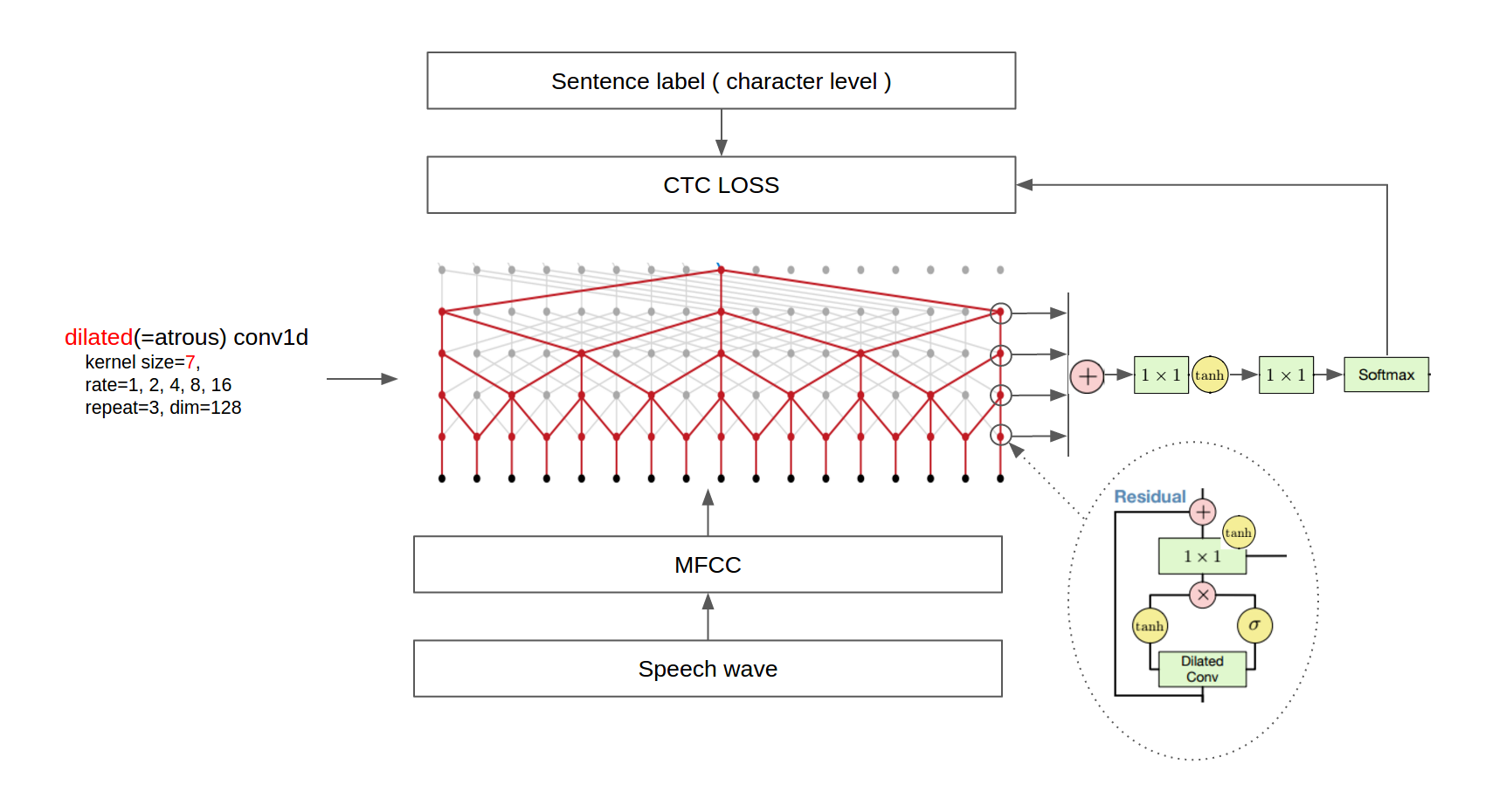
My practice is based on THCHS-30. Because there is not enough time to optimize the parameter of the model. At present, the recognition accuracy is not high. This repository will continue to update as a record.
- CTC is the standard configuration of the end to end speech recognition system nowadays. It solves the one-to-multiply mapping problem of text sequence and output of neural network model, therefore can help construct end to end system.
- The research on the 11 convolution kernal was first seen in the 14 year paper *Network In Network, and was later carried forward by Google in the Inception model. It can integrate information from multi channels for nonlinear transformation, and can increase or reduce dimensions of channels(all convolution kernal can change dimensions of channels, but the advantage of 1*1 kernal is that it uses least parameters), thus can jump links in neural network models.
- In ResNets, a “shortcut” or a “skip connection” allows the gradient to be directly backpropagated to earlier layers.By stacking ResNet blocks on top of each other, you can form a very deep network.
- The classic gate structure in the LSTM model can effectively extract input information and use it in long length (long time) effective information correlation architecture, such as Natural Language Processing.
- A dilated convolution is a convolution where the filter is applied over an area larger than its length by skipping input values with a certain step. A dilated convolution effectively allows the network to operate on a coarser scale than with a normal convolution.
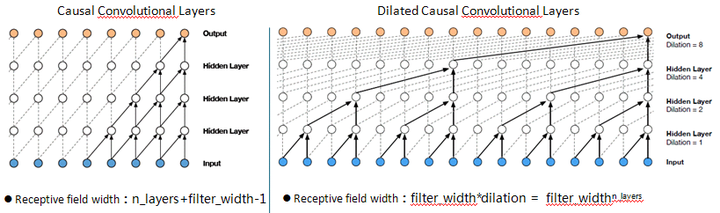
As shown above, the network layer in the model(n_layers) is 4, the size of the convolution kernel(filter_width) is 2, the classical CNN model, receptive field size is 2+4-1=5, using only input data of 5 dimensional information, and the dilated CNN model of receptive field size is the fourth power of 2(16). This is similar to pooling or strided convolutions, but here the output has the same size as the input.
The strategies implemented in the codes includes:
- Xavier initialization
- Shuffle data for each epoch
- Batch normalization
- 3 blocks is implemented, each contains 5 dilated convolutional layers.
- Adam optimizer
Version
Current version: 0.0.1(Draft)
Prerequisites
- python 3.5
- tensorflow 1.0.0
- librosa 0.5.0
Dataset
Directories
- cache: save data feature and word dictionary
- data: wav files and related labels
- model: save the models
Network model
- Data random shuffle per epoch
- Xavier initialization
- Adam optimization algorithms
- Batch Normalization
Train the network
python3 train.py
Test the network
python3 test.py
References
- TensorFlow练习15: 中文语音识别
- ibab’s WaveNet(speech synthesis) tensorflow implementation
- buriburisuri’s WaveNet(English speech recognition) tensorflow and sugartensor implementation